Heterogeneous cluster
A heterogeneous cluster system can be efficiently applied to applications with various computation requirements and memory access patterns, since different kinds of processing units have better performance over others for given computation tasks, and tightly-coupled hardware accelerators inside a node can reduce communication requirement by computing locally. Overall system performance can be improved by allowing the heterogeneous cores working collaboratively on different parts of an application. The challenges here are providing efficient communication, load balancing and ease of porting applications.
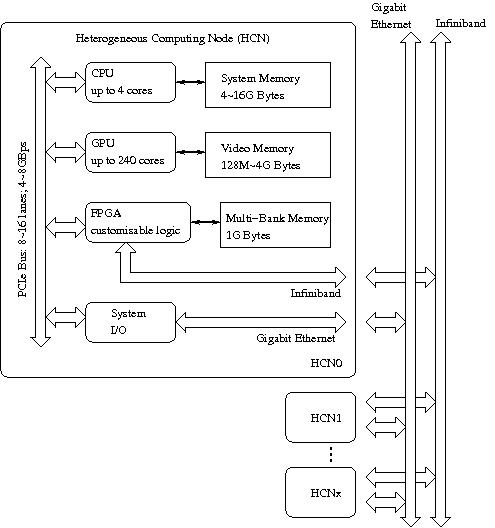
The AXEL project targets a high performance and high availability heterogeneous cluster including CPU, GPU and FPGA as primary computing elements. It is intended to be a prototype of a next-generation high-performance system in, for example, data centres, as shown in the following figure.
Processing Elements
Flexible FPGA

The advantage of using FPGAs for demanding tasks is based on programmable hardware resources and flexible I/O connections. Also, the overhead of communication can be minimized as all functions can be customized for specific applications. Unlike a CPU or a GPU, the datapath in FPGAs can be customised to meet different application requirements, and in many cases no instruction fetch and decode is needed.
Many-core GPU

Computation-oriented GPUs support massively parallel floating point arithmeic in the system. Thousand of threads are executed in the GPU with hardware assisted zero overhead context switching. These GPUs differ from traditional SIMD or vector processors by having a highly-capable streaming engine for data processing instead of a simple ALU. Application programmers can use these GPU accelerators without learning a new language and without knowing electronic design techniques.
Multi-core CPU

After reaching the limit of clock frequency of existing silicon resources, multicore technology further improves CPU performance by exploring parallel operations in increased silicon area. To utilize available parallelism, new programming frameworks are needed to support multi-threading. The latest CPU cores, with advanced support of instruction-level parallelism and local cache memory, are ideal for complicated algorithms with unpredictable branching and non-uniform memory access patterns.
Acknowledgement
The generous support of Alpha Data, Xilinx, nVidia, UK Engineering and Physical Sciences Research Council, and an Imperial College Research Excellence Award is gratefully acknowledged.